
传统数据中心当年主要用于数据的存储、检索与处置。但在生成式 AI 与代理式 AI 时期,这些措施已演变为 AI Token 工场。跟着 AI 推理成为其中枢责任负载,它们的主要产出已回荡为以 Token 样式制造的智能。
这一溜变也需要对包括总体领有成本(TCO)在内的 AI 基础措施的经济效益评估的时势相应地进行退换。然而,在评估 AI 基础措施时,企业仍过于柔和芯片峰值规格、筹备成本,或每好意思元所能取得的浮点运算性能,即每好意思元 FLOPS。
要道永别在于:
算力成本是企业为 AI 基础措施所支付的用度,不管是从云劳动提供商租用,仍是在腹地自建部署。
每好意思元 FLOPS 揣摸的是企业每插足一好意思元所取得的原始算力,但原始算力并不等同于现实天下中的 Token 产出。
每 Token 成本指的是企业生成并委用每一个 Token 的详尽成本,频繁以每百万 Token 成原本默示。
前两者仅是插足贪图。但当业务围绕产出运转时,只针对插足优化,施行上是一种根人性的错配。
每 Token 成本决定了企业能否完了 AI 的边界化盈利。它是独一粗疏平直详尽反应硬件性能、软件优化、生态系统支捏以及施行行使率的 TCO 贪图,而 NVIDIA 在这一贪图上完了了行业最低的每 Token 成本。
粗疏裁减每 Token 成本的身分有哪些?
要意会奈何优化每 Token 成本,领先需要了解用于筹备“每百万 Token 成本”的筹备公式。

在这个公式中,好多评估 AI 基础措施的企业陆续只柔和分子项,即每 GPU 每小时成本。关于云部署而言,这对应支付给云劳动提供商的小时用度;而关于腹地部署,则是通过摊销自有基础措施得到的等效小时成本。然而,裁减每 Token 成本的要道在于分母,即最大化施行委用的 Token 产出。
这个分母传递了两层生意含义:
最小化每 Token 成本:当 Token 产出加多被代入公式时,将裁减每 Token 成本,从而擢升每一次交互劳动的利润空间。
最大化收入:每秒委用更多 Token,博亚体育中国官网在线入口也意味着每兆瓦产出更多的 Token,这将带来更高的智能供给才能,使 AI 驱动的居品与劳动粗疏在相易基础措施插操纵创造更高收入。
因此,如若只柔和分子,就会淡薄实在决定分母的身分。不错将其意会为一个“推理冰山”:分子位于水面之上,直不雅可见且易于横向比拟;而分母则掩盖在水面之下,那才是决定施行 Token 产出的要道身分。对 AI 基础措施的准确评估,应从酌量水面之下的部分运行。

上层问题:
每 GPU 小时的成本是若干?
峰值 PetaFLOPS 性能和高带宽内存容量是若干?
每好意思元可取得若干 FLOPS?
深度成分内析:
每百万 Token 的成本是若干?尤其是针对大边界羼杂大众(MoE)推理模子(现时部署最庸俗的一类 AI 模子),其每百万 Token 成本是若干?
每兆瓦可委用若干 Token 产出?尤其是对腹地部署而言,由于在地盘、电力与基础措施上的老本插足较大,最大化每兆瓦所产生的智能产出至关艰辛。
纵向膨胀(scale-up)互连是否粗疏撑捏 MoE 模子所需的“all-to-all”通讯模式?
是否支捏 FP4 精度?推理栈是否粗疏在保捏高精度的同期充分行使 FP4?
推理运行时是否支捏投契解码或多 Token 瞻望,米兰app官方网站以擢升用户交互体验?
劳动层是否支捏解耦劳动、KV 感知路由、KV 缓存卸载以过火他优化?
平台是否支捏代理式 AI 的专有责任负载需求,包括超低延长、高混沌以及长输入序列长度等?
平台是否支捏从考试、后考试到大边界推理的完好生命周期,并覆盖统共模子架构,从而完了基础措施可互换性与高行使率?
这些算法、硬件与软件化中的每一项优化都必须灵验何况是不错相互集成的,不然分母项将无法成立。一块看似“更低廉”的 GPU,如若其每秒 Token 产出数目显豁更低,反而会导致更高的每 Token 成本。粗疏作念到全栈实在优化的 AI 基础措施,才粗疏确保每项优化都相互增强,从而捏续擢升举座成果。
为什么每 Token 成本比每好意思元 FLOPS 更艰辛?
以下DeepSeek-R1 AI模子的数据展示了表面贪图与施行生意摈弃之间的各别。
仅从算力成原本看,NVIDIA Blackwell 平台的成本似乎约为 NVIDIA Hopper 的 2 倍,但算力成本并不成评释这项插足究竟能带来若干施行产出。如若仅以每好意思元 FLOPS 进行分析,相较于 NVIDIA Hopper 架构,NVIDIA Blackwell 仅有约 2 倍上风。然而,施行摈弃却呈现出数目级各别:Blackwell 每瓦的 Token 产出量是 Hopper 的 50 倍以上,每百万 Token 的成本裁减至其 1/35 傍边。
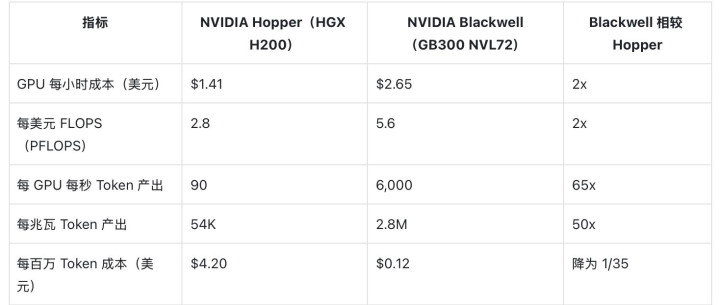
注:数据开头于 NVIDIA 分析报谈及 SemiAnalysis InferenceX v2 基准测试。
这一悬殊各别标明,相较于上一代 Hopper,NVIDIA Blackwell 在生意价值上完了了纷乱的跃迁,其擢升幅度远超系统成本的加多。
奈何选拔顺应的 AI 基础措施?
仅凭算力成本或每好意思元表面 FLOPS 来比拟 AI 基础措施,不仅是不充分的,也无法简直反应推理经济学。正如数据所展示的,要准确评估 AI 基础措施的营收后劲与盈利才能,需将揣摸维度从输入贪图转向每 Token 成本和施行 Token 产出量。
NVIDIA 通过在筹备、齐集、内存、存储、软件以及合营伙伴技艺上的极致协同瞎想,完了了业内最低的 Token 成本与最高的 Token 混沌量。此外,诸如 vLLM、SGLang、NVIDIA TensorRT-LLM 以及 NVIDIA Dynamo 等基于 NVIDIA 平台构建的开源推理软件的捏续优化,意味着在现存 NVIDIA 基础措施部署后,Token 产出仍可不休擢升,每 Token 成本会捏续下落。
跳动的云劳动提供商与 NVIDIA 云合营伙伴,已在边界化部署中充分体现这一上风。包括 CoreWeave、Nebius、Nscale 与 Together AI 在内的合营伙伴,已部署 NVIDIA Blackwell 基础措施,并对其技艺栈进行了优化米兰app2026世界杯中国官网,为企业提供现时最低的 Token 成本,同期充分融会 NVIDIA 在硬件、软件与生态系统协同瞎想方面的一王人上风,使每一次 AI 交互的处置都建树在这一完好体系之上。
 备案号:
备案号: